rowwise(): This function is used to indicate that operations following it should be applied row by row instead of column by column (which is the default behavior in dplyr).
Within the mutate() function, sum(c_across(contains("totals_"))) computes the sum of all columns for each row that contain the pattern “totals_”.
The na.rm = TRUE argument is used to ignore NA values in the sum. c_across() is used to select columns within rowwise() context.
ungroup(): This function is used to remove the rowwise grouping imposed by rowwise(), returning the dataframe to a standard tbl_df.
Usually I forget to ungroup. Oops. But this is important for performance reasons and because most dplyr functions expect data not to be in a rowwise format.
Create a rowwise binary variable
data <- data %>%
rowwise() %>%
mutate(has_ruler = as.integer(any(c_across(starts_with("broad_cat_")) == "ruler"))) %>%
ungroup()
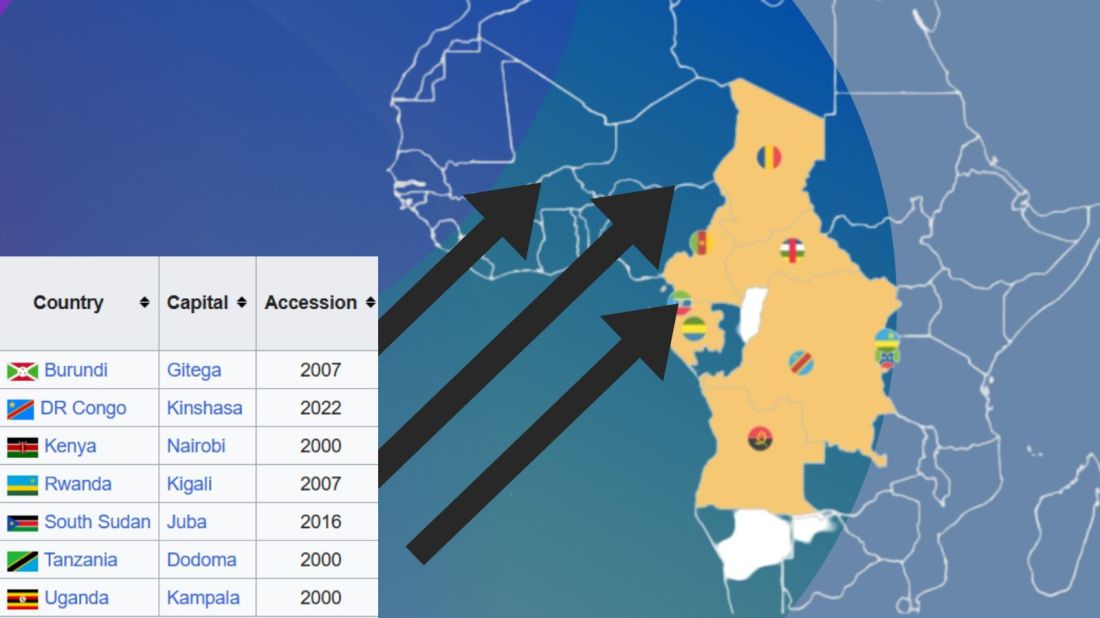
There are eight RECs in Africa. Some countries are only in one of the RECs, some are in many. Kenya is the winner with membership in four RECs: CEN-SAD, COMESA, EAC and IGAD.
In this blog, we will create a consolidated dataset for all 54 countries in Africa that are in a REC (or TWO or THREE or FOUR groups). Instead of a string variable for each group, we will create eight dummy group variables for each country.
To do this, we first make a vector of all the eight RECs.
We put the vector of patterns in a for-loop to create a new binary variable column for each REC group.
We use the str_detect(rec_abbrev, pattern)) to see if the rec_abbrev column MATCHES the one of the above strings in the patterns vector.
The new variable will equal 1 if the variable string matches the pattern in the vector. Otherwise it will be equal to 0.
The double exclamation marks (!!) are used for unquoting, allowing the value of var_name to be treated as a variable name rather than a character string.
Then, we are able to create a variable name that were fed in from the vector dynamically into the for-loop. We can automatically do this for each REC group.
In this case, the iterated !!var_name will be replaced with the value stored in the var_name (AMU, CEN-SAD etc).
We can use the := to assign a new variable to the data frame.
The symbol := is called the “walrus operator” and we use it make or change variables without using quotation marks.
for (pattern in patterns) {
var_name <- paste0(pattern, "_binary")
rec <- rec %>%
mutate(!!var_name := as.integer(str_detect(rec_abbrev, pattern)))
}
This is the dataset now with a binary variables indicating whether or not a country is in any one of the REC groups.
However, we quickly see the headache.
We do not want four rows for Kenya in the dataset. Rather, we only want one entry for each country and a 1 or a 0 for each REC.
We use the following summarise() function to consolidate one row per country.
The first() function extracts the first value in the geo variable for each country. This first() function is typically used with group_by() and summarise() to get the value from the first row of each group.
We use the the across() function to select all columns in the dataset that end with "_binary".
The ~ as.integer(any(. == 1)) checks if there’s any value equal to 1 within the binary variables. If they have a value of 1, the summarised data for each country will be 1; otherwise, it will be 0.
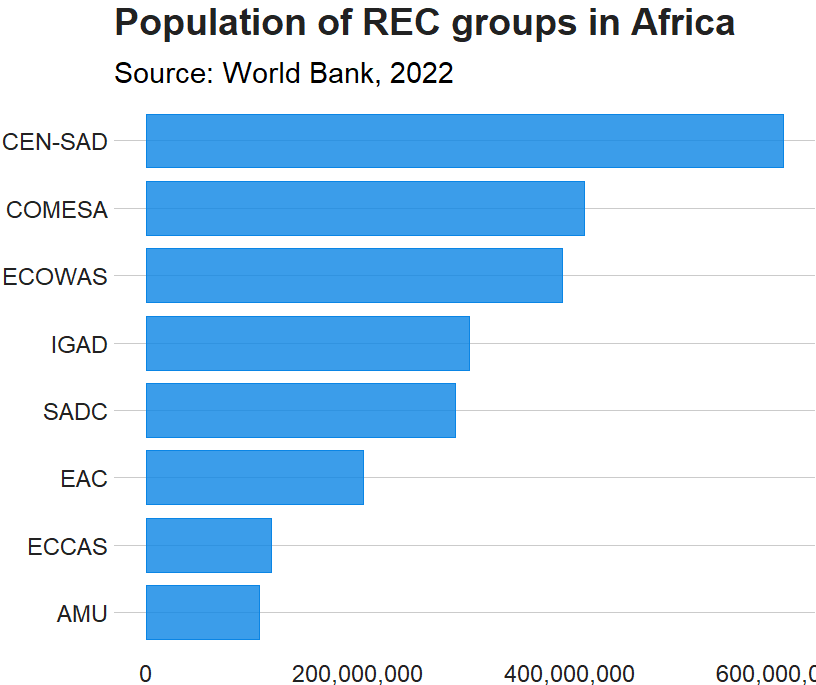
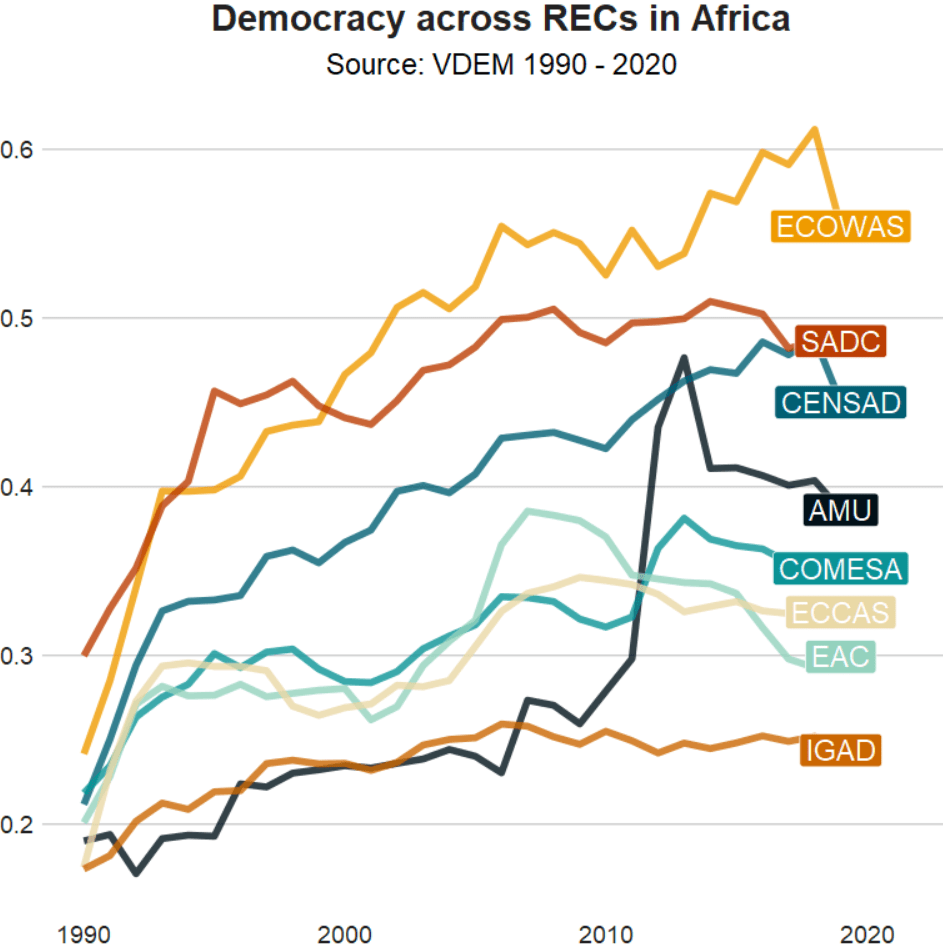
The following code can summarise each filtered group and add them to a new dataset that we can graph: