Packages we will need:
library(cluster)
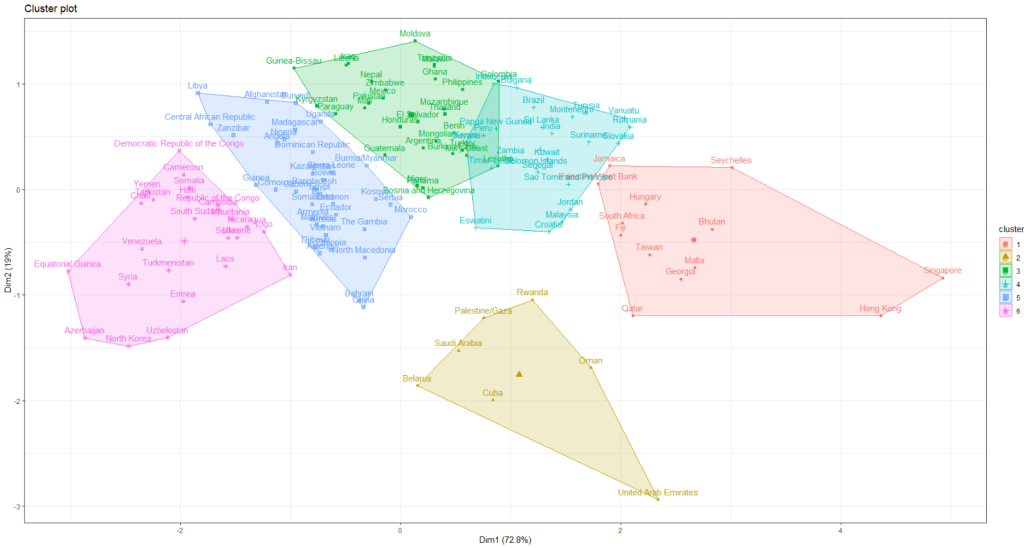
library(factoextra)I am looking at 127 non-democracies on seeing how the cluster on measures of state capacity (variables that capture ability of the state to control its territory, collect taxes and avoid corruption in the executive).
We want to minimise the total within sums of squares error from the cluster mean when determining the clusters.
First, we need to find the optimal number of clusters. We set the max number of clusters at k = 15.
within_sum_squares <- function(k){kmeans(autocracy_df, k, nstart = 3)$tot.withinss}
min_max <- 1:15
within_sum_squares_values <- map(min_max, within_sum_squares)
plot(min_max, within_sum_squares_values,
type="b", pch = 19, frame = FALSE,
xlab="Number of clusters",
ylab="Total within sum of squares")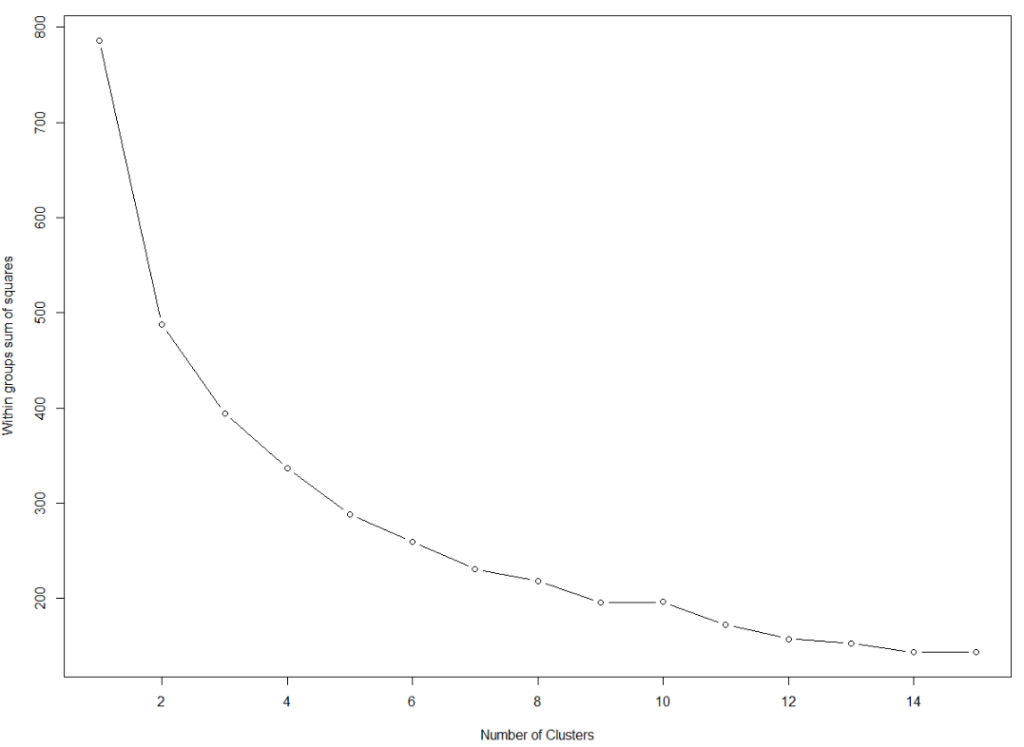
K-means searches for the minimum sum of squares assignment, i.e. it minimizes unnormalized variance by assigning points to cluster centers.
k_clusters <- kmeans(autocracy_df[3:5], centers = 6, nstart = 25)
class(k_clusters)We can now take the k_clusters object and feed it into the fviz_cluster() function.
fviz_cluster(k_clusters, data = autocracy_df[3:5], ellipse.type = "convex")