Packages we will need:
library(sandwich)
library(stargazer)
library(lmtest)
If our OLS model demonstrates high level of heteroskedasticity (i.e. when the error term of our model is not randomly distributed across observations and there is a discernible pattern in the error variance), we run into problems.
Why? Because this means OLS will use sub-optimal estimators based on incorrect assumptions and the standard errors computed using these flawed least square estimators are more likely to be under-valued.
Since standard errors are necessary to compute our t – statistic and arrive at our p – value, these inaccurate standard errors are a problem.
Click here to check for heteroskedasticity in your model with the lmtest package.
To correct for heteroskedastcity in your model, you need the sandwich package and the lmtest package to employ the vcocHC argument.

First, let’s fit a simple OLS regression.
summary(free_express_model <- lm(freedom_expression ~ free_elections + deliberative_index, data = data_1990))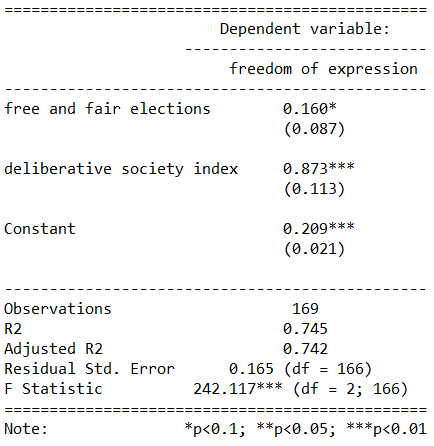
We can see that there is a small star beside the main dependent variable of interest! Success!

We have significance.
Thus, we could say that the more free and fair the elections a country has, this increases the mean freedom of expression index score for that country.
This ties in with a very minimalist understanding of democracy. If a country has elections and the populace can voice their choice of leadership, this will help set the scene for a more open society.
However, it is naive to look only at the p – value of any given coefficient in a regression output. If we run some diagnostic analyses and look at the relationship graphically, we may need to re-examine this seemingly significant relationship.
Can we trust the 0.087 standard error score that our OLS regression calculated? Is it based on sound assumptions?

First let’s look at the residuals. Can we assume that the variance of error is equal across all observations?

If we examine the residuals (the first graph), we see that there is actually a tapered fan-like pattern in the error variance. As we move across the x axis, the variance along the y axis gets continually smaller and smaller.
The error does not look random.

Let’s run a Breush-Pagan test (from the lmtest package) to check our suspicion of heteroskedasticity.
lmtest::bptest(free_exp_model)
We can reject the null hypothesis that the error variance is homoskedastic.
So the model does suffer from heteroskedasticty. We cannot trust those stars in the regression output!

In order to fix this and make our p-values more accuarate, we need to install the sandwich package to feed in the vcovHC adjustment into the coeftest() function.
vcovHC stands for variance covariance Heteroskedasticity Consistent.
With the stargazer package (which prints out all the models in one table), we can compare the free_exp_model alone with no adjustment, then four different variations of the vcovHC adjustment using different formulae (as indicated in the type argument below).
stargazer(free_exp_model,
coeftest(free_exp_model, vcovHC(free_exp_model, type = "HC0")),
coeftest(free_exp_model, vcovHC(free_exp_model, type = "HC1")),
coeftest(free_exp_model, vcovHC(free_exp_model, type = "HC2")),
coeftest(free_exp_model, vcovHC(free_exp_model, type = "HC3")),
type = "text")
Looking at the standard error in the (brackets) across the OLS and the coeftest models, we can see that the standard error are all almost double the standard error from the original OLS regression.
There is a tiny difference between the different types of Heteroskedastic Consistent (HC) types.
The significant p – value disappears from the free and fair election variable when we correct with the vcovHC correction.

The actual coefficient stays the same regardless of whether we use no correction or any one of the correction arguments.
Which HC estimator should I use in my vcovHC() function?
The default in the sandwich package is HC3.
STATA users will be familiar with HC1, as it is the default robust standard error correction when you add robust at the end of the regression command.
The difference between them is not very large.
The estimator HC0 was suggested in the econometrics literature by White in 1980 and is justified by asymptotic arguments.
For small sample sizes, the standard errors from HC0 are quite biased, usually downward, and this results in overly liberal inferences in regression models (Bera, Suprayitno & Premaratne, 2002). But with HC0, the bias shrinks as your sample size increases.
The estimator types HC1, HC2 and HC3 were put forward by MacKinnon and White (1985) to improve the performance in small samples.
Long and Ervin (2000) furthermore argue that HC3 provides the best performance in small samples as it gives less weight to influential observations in the model
In our freedom of expression regression, the HC3 estimate was the most conservative with the standard error calculations. however the difference between the approaches did not change the conclusion; ultimately the main independent variable of interest in this analysis – free and fair elections – can explain variance in the dependent variable – freedom of expression – does not find evidence in the model.
Click here to read an article by Hayes and Cai (2007) which discusses the matrix formulae and empirical differences between the different calculation approaches taken by the different types. Unfortunately it is all ancient Greek to me.
References
Bera, A. K., Suprayitno, T., & Premaratne, G. (2002). On some heteroskedasticity-robust estimators of variance–covariance matrix of the least-squares estimators. Journal of Statistical Planning and Inference, 108(1-2), 121-136.
Hayes, A. F., & Cai, L. (2007). Using heteroskedasticity-consistent standard error estimators in OLS regression: An introduction and software implementation. Behavior research methods, 39(4), 709-722.
Long, J. S., & Ervin, L. H. (2000). Using heteroscedasticity consistent standard errors in the linear regression model. The American Statistician, 54(3), 217-224.
MacKinnon, J. G., & White, H. (1985). Some heteroskedasticity-consistent covariance matrix estimators with improved finite sample properties. Journal of econometrics, 29(3), 305-325.

!
LikeLike