In this blog post, we will cross-validate different boosted tree models and find the one with best root mean square error (RMSE).
Specifically, part 2 goes into more detail about RMSE as a way to choose the best model
Click here to read part 1, part 2 or part 3 of this series on tidymodel package stuff.
Packages we will need:
library(tidymodels)
library(tidyverse)Our resampling method will be 10-fold cross-validation.
Click here to watch a Youtube explainer by StatQuest on the fundamentals of cross validation. StatQuest is the cat’s pyjamas.
We can use the vfold_cv() function to create a set of “V-fold” cross-validation with 11 splits.
My favorite number is 11 so I’ll set that as the seed too.
set.seed(11)
cross_folds <- vfold_cv(vdem_1990_2019, v = 11)We put our formula into the recipe function and run the pre-processing steps: in this instance, we are just normalizing the variables.
my_recipe <- recipe(judic_corruption ~ freedom_religion + polarization,
data = vdem_1990_2019) %>%
step_normalize(all_predictors(), -all_outcomes())Here, we will initially define a boost_tree() model without setting any hyperparameters.
This is our baseline model with defaults.
With the vfolds, we be tuning them and choosing the best parameters.
For us, our mode is “regression” (not categorical “classification”)
my_tree <- boost_tree(
mode = "regression",
engine = "xgboost") %>%
set_engine("xgboost") %>%
set_mode("regression")Next we will set up a grid to explore a range of hyperparameters.
my_grid <- grid_latin_hypercube(
trees(range = c(500, 1500)),
tree_depth(range = c(3, 10)),
learn_rate(range = c(0.01, 0.1)),
size = 20)We use the grid_latin_hypercube() function from the dials package in R is used to generate a sampling grid for tuning hyperparameters using a Latin hypercube sampling method.
Latin hypercube sampling (LHS) is a way to generate a sample of plausible, semi-random collections of parameter values from a distribution.
This method is used to ensure that each parameter is uniformly sampled across its range of values. LHS is systematic and stratified, but within each stratum, it employs randomness.

Inside the grid_latin_hypercube() function,we can set the ranges for the model parameters,
trees(range = c(500, 1500))
This parameter specifies the number of trees in the model
We can set a sampling range from 500 to 1500 trees.
tree_depth(range = c(3, 10))
This defines the maximum depth of each tree
We set values ranging from 3 to 10.
learn_rate(range = c(0.01, 0.1))
This parameter controls the learning rate, or the step size at each iteration while moving toward a minimum of a loss function.
It’s specified to vary between 0.01 and 0.1.
size = 20
We want the Latin Hypercube Sampling to generate 20 unique combinations of the specified parameters. Each of these combinations will be used to train a model, allowing for a systematic exploration of how different parameter settings impact model performance.
> my_grid
# A tibble: 20 × 3
trees tree_depth learn_rate
<int> <int> <dbl>
1 803 7 1.03
2 981 7 1.18
3 862 6 1.09
4 1185 9 1.06
5 763 8 1.13
6 593 4 1.11
7 524 7 1.22
8 743 3 1.17
9 1347 5 1.07
10 1010 5 1.15
11 677 3 1.25
12 1482 5 1.05
13 1446 8 1.12
14 917 4 1.23
15 1296 6 1.04
16 1391 8 1.23
17 1106 9 1.18
18 1203 5 1.14
19 606 10 1.20
20 1088 9 1.10
So next, we will combine our recipe, model specification, and resampling method in a workflow, and use tune_grid() to find the best hyperparameters based on RMSE.
my_workflow <- workflow() %>%
add_recipe(my_recipe) %>%
add_model(my_tree)The tune_grid() function does the hyperparameter tuning. We will make different combinations of hyperparameters specified in grid using cross-validation.
tuning_results <- my_workflow %>%
tune_grid(
resamples = cv_folds,
grid = my_grid,
metrics = metric_set(rmse))
# Tuning results
# 10-fold cross-validation
# A tibble: 10 × 4
splits id .metrics .notes
<list> <chr> <list> <list>
1 <split [3200/356]> Fold01 <tibble [1 × 4]> <tibble [0 × 3]>
2 <split [3200/356]> Fold02 <tibble [1 × 4]> <tibble [0 × 3]>
3 <split [3200/356]> Fold03 <tibble [1 × 4]> <tibble [0 × 3]>
4 <split [3200/356]> Fold04 <tibble [1 × 4]> <tibble [0 × 3]>
5 <split [3200/356]> Fold05 <tibble [1 × 4]> <tibble [0 × 3]>
6 <split [3200/356]> Fold06 <tibble [1 × 4]> <tibble [0 × 3]>
7 <split [3201/355]> Fold07 <tibble [1 × 4]> <tibble [0 × 3]>
8 <split [3201/355]> Fold08 <tibble [1 × 4]> <tibble [0 × 3]>
9 <split [3201/355]> Fold09 <tibble [1 × 4]> <tibble [0 × 3]>
10 <split [3201/355]> Fold10 <tibble [1 × 4]> <tibble [0 × 3]>
After tuning, we can extract and examine the best models.
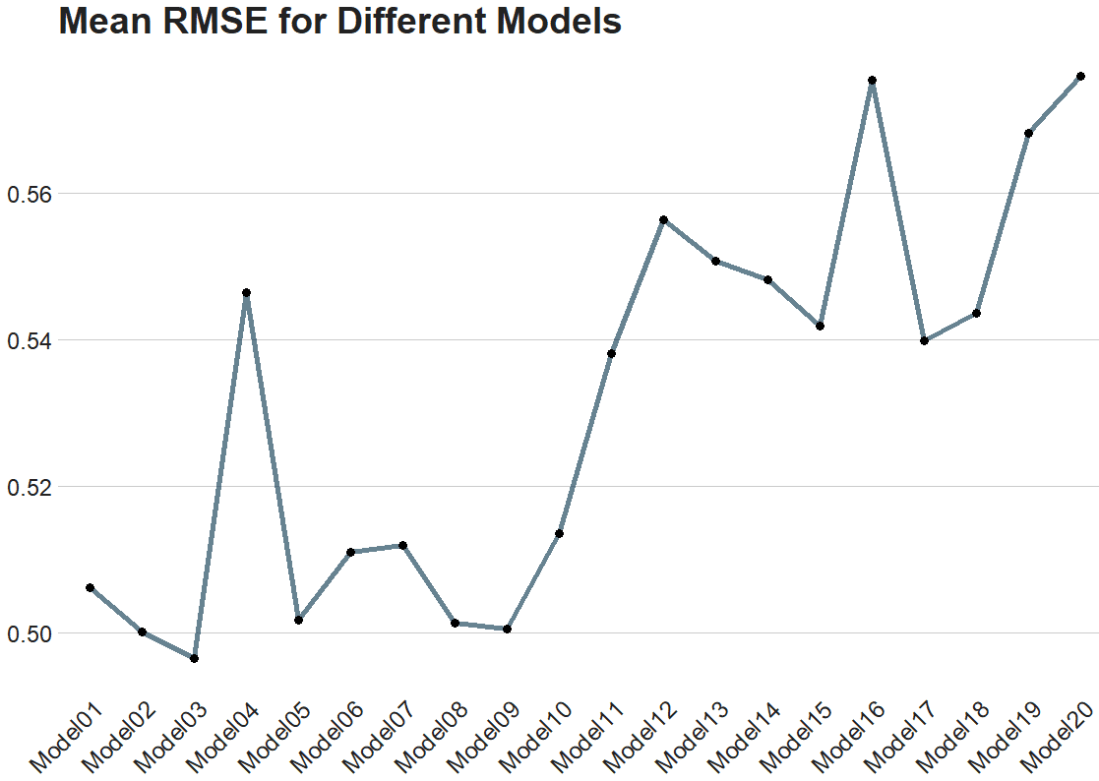
show_best(tuning_results, metric = "rmse")
trees tree_depth learn_rate .metric .estimator mean n std_err .config
<int> <int> <dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
1 593 4 1.11 rmse standard 0.496 10 0.0189 Preprocessor1_Model03
2 677 3 1.25 rmse standard 0.500 10 0.0216 Preprocessor1_Model02
3 1296 6 1.04 rmse standard 0.501 10 0.0238 Preprocessor1_Model09
4 1010 5 1.15 rmse standard 0.501 10 0.0282 Preprocessor1_Model08
5 1482 5 1.05 rmse standard 0.502 10 0.0210 Preprocessor1_Model05
The best model is model number 3!

Finally, we can plot it out.
We use collect_metrics() to pull out the RMSE and other metrics from our samples.
It automatically aggregates the results across all resampling iterations for each unique combination of model hyperparameters, providing mean performance metrics (e.g., mean accuracy, mean RMSE) and their standard errors.
rmse_results <- tuning_results %>%
collect_metrics() %>%
filter(.metric == "rmse")rmse_results %>%
mutate(.config = str_replace(.config, "^Preprocessor1_", "")) %>%
ggplot(aes(x = .config, y = mean)) +
geom_line(aes(group = 1), color = "#023047", size = 2, alpha = 0.6) +
geom_point(size = 3) +
bbplot::bbc_style() +
labs(title = "Mean RMSE for Different Models") +
theme(axis.text.x = element_text(angle = 45, hjust = 1))