Packages we will need
library(tidyverse)
library(peacesciencer)
library(countrycode)
library(bbplot)
The main workhorse of this blog is the peacesciencer package by Stephen Miller!
The package will create both dyad datasets and state datasets with all sovereign countries.
Thank you Mr Miller!
There are heaps of options and variables to add.
Go to the page to read about them all in detail.
Here is a short list from the package description of all the key variables that can be quickly added:

We create the dyad dataset with the create_dyadyears() function. A dyad-year dataset focuses on information about the relationship between two countries (such as whether the two countries are at war, how much they trade together, whether they are geographically contiguous et cetera).
In the literature, the study of interstate conflict has adopted a heavy focus on dyads as a unit of analysis.
Alternatively, if we want just state-year data like in the previous blog post, we use the function create_stateyears()
We can add the variables with type D to the create_dyadyears() function and we can add the variables with type S to the create_stateyears() !
Focusing on the create_dyadyears() function, the arguments we can include are directed and mry.
The directed argument indicates whether we want directed or non-directed dyad relationship.
In a directed analysis, data include two observations (i.e. two rows) per dyad per year (such as one for USA – Russia and another row for Russia – USA), but in a nondirected analysis, we include only one observation (one row) per dyad per year.
The mry argument indicates whether they want to extend the data to the most recently concluded calendar year – i.e. 2020 – or not (i.e. until the data was last available).
dyad_df <- create_dyadyears(directed = FALSE, mry = TRUE) %>%
add_atop_alliance() %>%
add_nmc() %>%
add_cow_trade() %>%
add_creg_fractionalization() I added dyadic variables for the
- ATOP alliances,
- national military capabilities (NMC) ,
- Correlates of War trade data and
- Composition of Religious and Ethnic Groups (CREG) ethnicity fractionalization data.
You can follow these links to check out the codebooks if you want more information about descriptions about each variable and how the data were collected!
The code comes with the COW code but I like adding the actual names also!
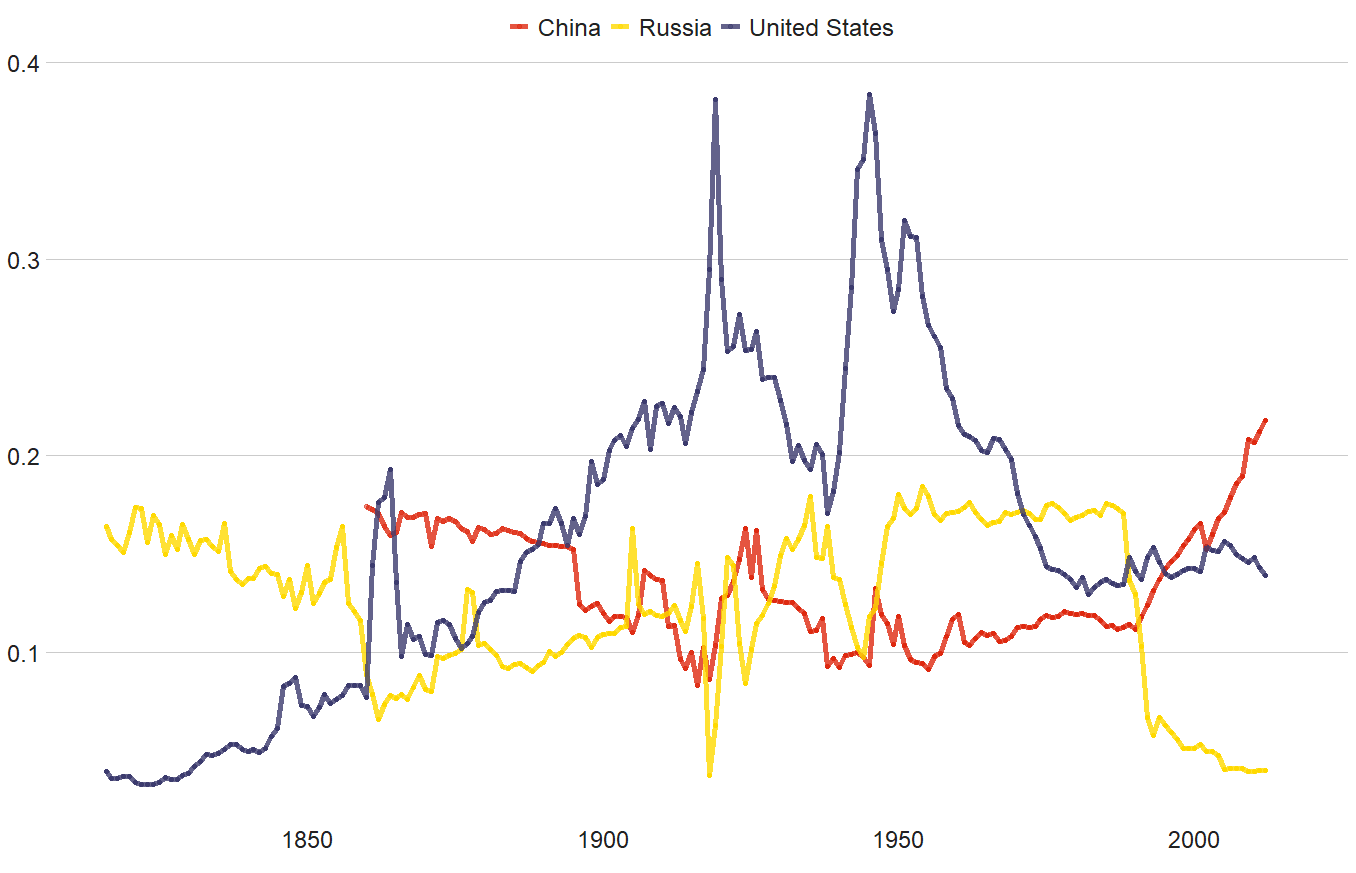
dyad_df$country_1 <- countrycode(dyad_df$ccode1, "cown", "country.name")With this dataframe, we can plot the CINC data of the top three superpowers, just looking at any variable that has a 1 at the end and only looking at the corresponding country_1!
According to our pals over at le Wikipedia, the Composite Index of National Capability (CINC) is a statistical measure of national power created by J. David Singer for the Correlates of War project in 1963. It uses an average of percentages of world totals in six different components (such as coal consumption, military expenditure and population). The components represent demographic, economic, and military strength
First, let’s choose some nice hex colors
pal <- c("China" = "#DE2910",
"United States" = "#3C3B6E",
"Russia" = "#FFD900")And then create the plot
dyad_df %>%
filter(country_1 == "Russia" |
country_1 == "United States" |
country_1 == "China") %>%
ggplot(aes(x = year, y = cinc1, group = as.factor(country_1))) +
geom_line(aes(color = country_1)) +
geom_line(aes(color = country_1), size = 2, alpha = 0.8) +
scale_color_manual(values = pal) +
bbplot::bbc_style()
In PART 3, we will merge together our data with our variables from PART 1, look at some descriptive statistics and run some panel data regression analysis with our different variables!

Awesome guide! Thanks a bunch!
I have a question… I’ve generated a dataframe via peacesciencer package but for some reason the total number of dyads is unbalanced (e.g. in 2016 we have 18915 dyads, while the balanced version should have either 137×137=18769 or 138×138=19044 dyads). That means that some of the country-country dyads are ommited.
Do you know why this happens? Might there be any problem with the package itself?
LikeLike
I think it could be that in some years, the countries may not exist (like the presence of South Sudan will be unbalanced across the years)? I’ll have a look and see ! Thank you for the heads up!
LikeLiked by 1 person