
Click here to read why need to add pspwght and pweight to the ESS data in Part 1.
Packages we will need:
library(survey)
library(srvy)
library(stargazer)
library(gtsummary)
library(tidyverse)Click here to learn how to access and download ESS round data for the thirty-ish European countries (depending on the year).
So with the essurvey package, I have downloaded and cleaned up the most recent round of the ESS survey, conducted in 2018.
We will examine the different demographic variables that relate to levels of trust in politicians across 29 European countries (education level, gender, age et cetera).
Before we create the survey weight objects, we can first make a bar chart to look at the different levels of trust in the different countries.
We can use the cut() function to divide the 10-point scale into three groups of “low”, “mid” and “high” levels of trust in politicians.
I also choose traffic light hex colors in color_palette vector and add full country names with countrycode() so it’s easier to read the graph
color_palette <- c("1" = "#f94144", "2" = "#f8961e", "3" = "#43aa8b")
round9$country_name <- countrycode(round9$country, "iso2c", "country.name")
trust_graph <- round9 %>%
dplyr::filter(!is.na(trust_pol)) %>%
dplyr::mutate(trust_category = cut(trust_pol,
breaks=c(-Inf, 3, 7, Inf),
labels=c(1,2,3))) %>%
mutate(trust_category = as.numeric(trust_category)) %>%
mutate(trust_pol_fac = as.factor(trust_category)) %>%
ggplot(aes(x = reorder(country_name, trust_category))) +
geom_bar(aes(fill = trust_pol_fac),
position = "fill") +
bbplot::bbc_style() +
coord_flip()
trust_graph <- trust_graph + scale_fill_manual(values= color_palette,
name="Trust level",
breaks=c(1,2,3),
labels=c("Low", "Mid", "High")) The graph lists countries in descending order according to the percentage of sampled participants that indicated they had low trust levels in politicians.
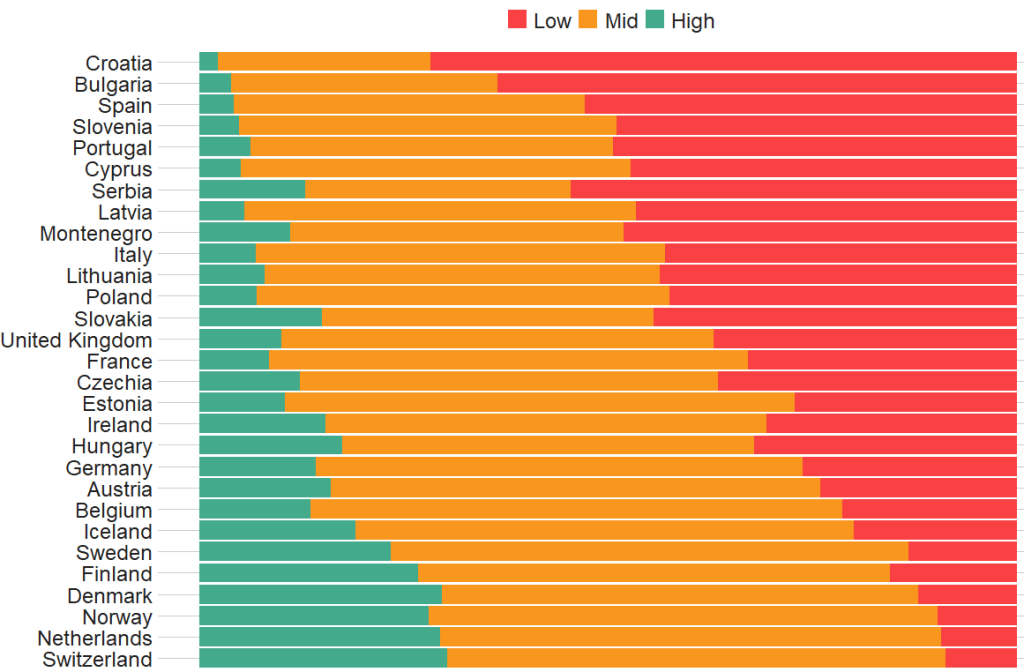
The respondents in Croatia, Bulgaria and Spain have the most distrust towards politicians.
For this example, I want to compare different analyses to see what impact different weights have on the coefficient estimates and standard errors in the regression analyses:
- with no weights (dEfIniTelYy not recommended by ESS)
- with post-stratification weights only (not recommended by ESS) and
- with the combined post-strat AND population weight (the recommended weighting strategy according to ESS)
First we create two special svydesign objects, with the survey package. To create this, we need to add a squiggly ~ symbol in front of the variables (Google tells me it is called a tilde).
The ids argument takes the cluster ID for each participant.
psu is a numeric variable that indicates the primary sampling unit within which the respondent was selected to take part in the survey. For example in Ireland, this refers to the particular electoral division of each participant.
The strata argument takes the numeric variable that codes which stratum each individual is in, according to the type of sample design each country used.
The first svydesign object uses only post-stratification weights: pspwght
Finally we need to specify the nest argument as TRUE. I don’t know why but it throws an error message if we don’t …
post_design <- svydesign(ids = ~psu,
strata = ~stratum,
weights = ~pspwght
data = round9,
nest = TRUE)To combine the two weights, we can multiply them together and store them as full_weight. We can then use that in the svydesign function
r2$full_weight <- r2$pweight*r2$pspwght
full_design <- svydesign(ids = ~psu,
strata = ~stratum,
weights = ~full_weight,
data = round9,
nest = TRUE)
class(full_design)With the srvyr package, we can convert a “survey.design” class object into a “tbl_svy” class object, which we can then use with tidyverse functions.
full_tidy_design <- as_survey(full_design)
class(full_tidy_design)Click here to read the CRAN PDF for the srvyr package.
We can first look at descriptive statistics and see if the values change because of the inclusion of the weighted survey data.
First, we can compare the means of the survey data with and without the weights.
We can use the gtsummary package, which creates tables with tidyverse commands. It also can take a survey object
library(gtsummary)
round9 %>% select(trust_pol, trust_pol, age, edu_years, gender, religious, left_right, rural_urban) %>%
tbl_summary(include = c(trust_pol, age, edu_years, gender, religious, left_right, rural_urban),
statistic = list(all_continuous() ~"{mean} ({sd})"))And we look at the descriptive statistics with the full_design weights:
full_design %>%
tbl_svysummary(include = c(trust_pol, age, edu_years, gender, religious, left_right),
statistic = list(all_continuous() ~"{mean} ({sd})"))
We can see that gender variable is more equally balanced between males (1) and females (2) in the data with weights
Additionally, average trust in politicians is lower in the sample with full weights.
Participants are more left-leaning on average in the sample with full weights than in the sample with no weights.
Next, we can look at a general linear model without survey weights and then with the two survey weights we just created.
Do we see any effect of the weighting design on the standard errors and significance values?
So, we first run a simple general linear model. In this model, R assumes that the data are independent of each other and based on that assumption, calculates coefficients and standard errors.
simple_glm <- glm(trust_pol ~ left_right + edu_years + rural_urban + age, data = round9)
Next, we will look at only post-stratification weights. We use the svyglm function and instead of using the data = r2, we use design = post_design .
post_strat_glm <- svyglm(trust_pol ~ left_right + edu_years + rural_urban + age, design = post_design) And finally, we will run the regression with the combined post-stratification AND population weight with the design = full_design argument.
full_weight_glm <- svyglm(trust_pol ~ left_right + edu_years + rural_urban + age, design = full_design))With the stargazer package, we can compare the models side-by-side:
library(stargazer)
stargazer(simple_glm, post_strat_glm, full_weight_glm, type = "text")
We can see that the standard errors in brackets were increased for most of the variables in model (3) with both weights when compared to the first model with no weights.
The biggest change is the rural-urban scale variable. With no weights, it is positive correlated with trust in politicians. That is to say, the more urban a location the respondent lives, the more likely the are to trust politicians. However, after we apply both weights, it becomes negative correlated with trust. It is in fact the more rural the location in which the respondent lives, the more trusting they are of politicians.
Additionally, age becomes statistically significant, after we apply weights.
Of course, this model is probably incorrect as I have assumed that all these variables have a simple linear relationship with trust levels. If I really wanted to build a robust demographic model, I would have to consult the existing academic literature and test to see if any of these variables are related to trust levels in a non-linear way. For example, it could be that there is a polynomial relationship between age and trust levels, for example. This model is purely for illustrative purposes only!
Plus, when I examine the R2 score for my models, it is very low; this model of demographic variables accounts for around 6% of variance in level of trust in politicians. Again, I would have to consult the body of research to find other explanatory variables that can account for more variance in my dependent variable of interest!
We can look at the R2 and VIF score of GLM with the summ() function from the jtools package. The summ() function can take a svyglm object. Click here to read more about various functions in the jtools package.

