Packages we will need:
library(rvest)
library(tidyverse)
library(magrittr)
library(forcats)
library(janitor)With the Korean Presidential elections coming up, I wanted to graph the polling data since the beginning of this year.

The data we can use is all collated together on Wikipedia.
Click here to read more about using the rvest package for scraping data from websites and click here to read the CRAN PDF for the package.
poll_html <- read_html("https://en.wikipedia.org/wiki/2022_South_Korean_presidential_election")
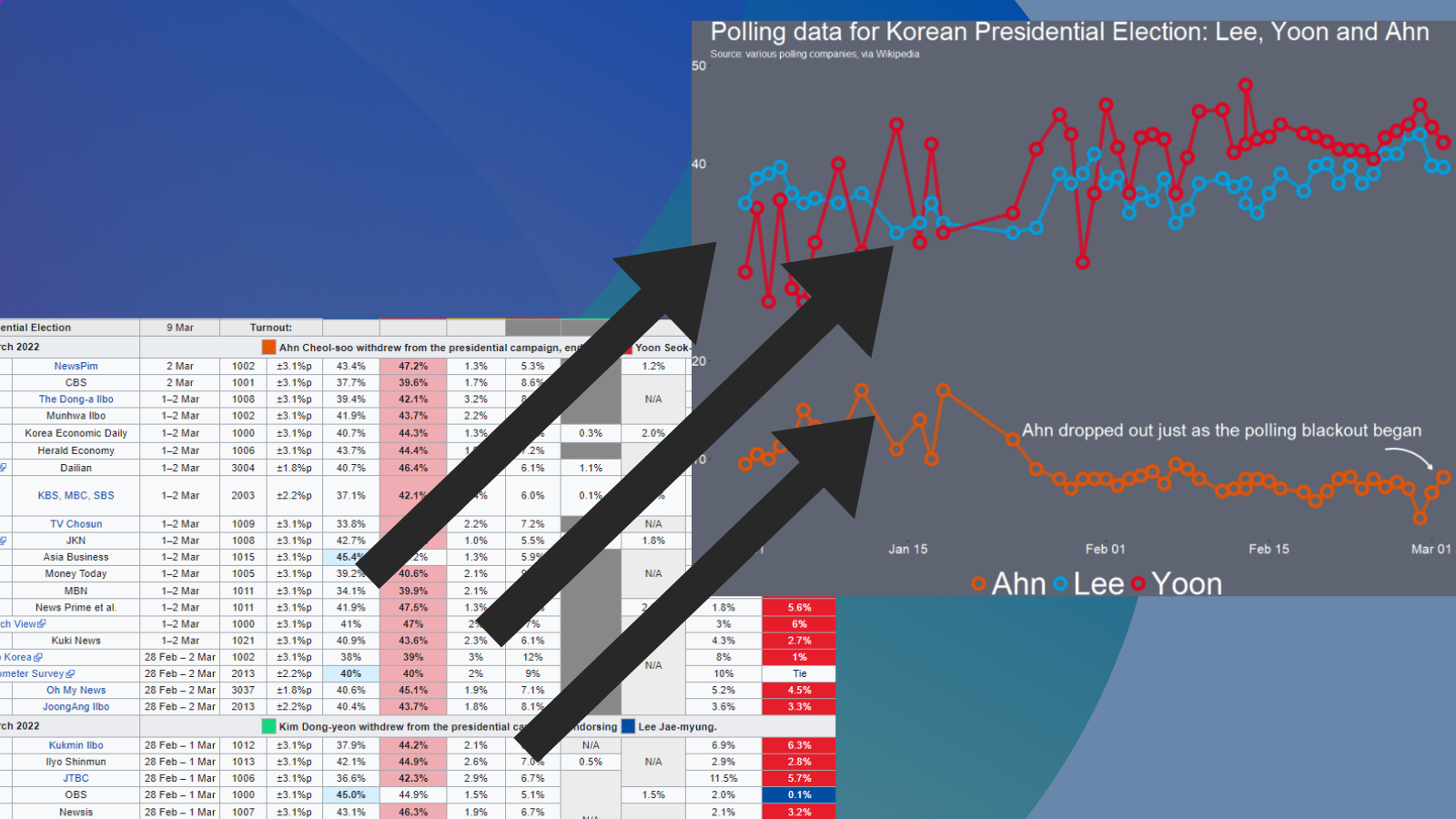
poll_tables <- poll_html %>% html_table(header = TRUE, fill = TRUE)There are 22 tables on the page in total.
I count on the page that the polling data is the 16th table on the page, so extract index [[16]] from the list
feb_poll <- poll_tables[[16]]
View(feb_poll)
It is a bit messy, so we will need to do a bit of data cleaning before we can graph.

First the names of many variables are missing or on row 2 / 3 of the table, due to pictures and split cells in Wikipedia.
[1] "Polling firm / Client" "Polling firm / Client" "Fieldwork date" "Sample size" "Margin of error"
[6] "" "" "" "" ""
[11] "" "Others/Undecided" "Lead"
The clean_names() function from the janitor package does a lot of the brute force variable name cleaning!
feb_poll %<>% clean_names()
We now have variable names rather than empty column names, at least.
[1] "polling_firm_client" "polling_firm_client_2" "fieldwork_date" "sample_size" "margin_of_error"
[6] "x" "x_2" "x_3" "x_4" "x_5"
[11] "x_6" "others_undecided" "lead"
We can choose the variables we want and rename the x variables with the names of each candidate, according to Wikipedia.
feb_poll %<>%
select(fieldwork_date,
Lee = x,
Yoon = x_2,
Shim = x_3,
Ahn = x_4,
Kim = x_5,
Heo = x_6,
others_undecided)We then delete the rows that contain text not related to the poll number values.
feb_poll = feb_poll[-25,]
feb_poll = feb_poll[-81,]
feb_poll = feb_poll[-1,]I want to clean up the fieldwork_date variable and convert it from character to Date class.
First I found that very handy function on Stack Overflow that extracts the last n characters from a string variable.
substrRight <- function(x, n){
substr(x, nchar(x)-n+1, nchar(x))
}
If we look at the table, some of the surveys started in Feb but ended in March. We want to extract the final section (i.e. the March section) and use that.
So we use grepl() to find rows that have both Feb AND March, and just extract the March section. If it only has one of those months, we leave it as it is.
feb_poll %<>%
mutate(clean_date = ifelse(grepl("Feb", fieldwork_date) & grepl("Mar", fieldwork_date), substrRight(fieldwork_date, 5), fieldwork_date))Next want to extract the three letter date from this variables and create a new month variable
feb_poll %<>%
mutate(month = substrRight(clean_date, 3)) Following that, we use the parse_number() function from tidyr package to extract the first number found in the string and create a day_number varible (with integer class now)
feb_poll %<>%
mutate(day_number = parse_number(clean_date)) We want to take these two variables we created and combine them together with the unite() function from tidyr again! We want to delete the variables after we unite them. But often I want to keep the original variables, so usually I change the argument remove to FALSE.
We indicate we want to have nothing separating the vales with the sep = "" argument
feb_poll %<>%
unite("date", day_number:month, sep = "", remove = TRUE)And we convert this new date into Date class with as.Date() function.
Here is a handy cheat sheet to help choose the appropriate % key so the format recognises the dates. I will never memorise these values, so I always need to refer to this site.
We have days as numbers (1, 2, 3) and abbreviated 3 character month (Jan, Feb, Mar), so we choose %d and %b
feb_poll %<>%
mutate(dates_format = as.Date(date, "%d%b")) %>%
select(dates_format, Lee:others_undecided) Next, we will use the pivot_longer() function to combine all the poll number values into one column. This will make it far easier to plot later.
feb_poll %<>%
pivot_longer(!dates_format, names_to = "candidate", values_to = "favour") After than, we need to clean the actual numbers, remove the percentage signs and convert from character to number class. We use the str_extract() and the regex code to extract the number and not keep the percentage sign.
feb_poll %<>%
mutate(candidate = as.factor(candidate),
favour_percent = str_extract(favour, "\\d+\\.*\\d*")) %>%
mutate(favour_percent = as.integer(favour_percent)) Some of the different polls took place on the same day. So we will take the average poll favourability value for each candidate on each day with the group_by() function
feb_poll %<>%
group_by(dates_format, candidate) %>%
mutate(favour_percent_mean = mean(favour_percent, na.rm = TRUE)) %>%
ungroup() %>%
select(candidate, dates_format, favour_percent_mean) And this is how the cleaned up data should look!

We repeat for the 17th and 16th tables, which contain data going back to the beginning of January 2022
early_feb_poll <- poll_tables[[17]]
early_feb_poll = early_feb_poll[-37,]
early_feb_poll = early_feb_poll[-1,]We repeat the steps from above with early Feb in one chunk
early_feb_poll %<>%
clean_names() %>%
mutate(month = substrRight(fieldwork_date, 3)) %>%
mutate(day_number = parse_number(fieldwork_date)) %>%
unite("date", day_number:month, sep = "", remove = FALSE) %>%
mutate(dates_format = as.Date(date, "%d%b")) %>%
select(dates_format,
Lee = lee_jae_myung,
Yoon = yoon_seok_youl,
Shim = sim_sang_jung,
Ahn = ahn_cheol_soo,
Kim = kim_dong_yeon,
Heo = huh_kyung_young,
others_undecided) %>%
pivot_longer(!dates_format, names_to = "candidate", values_to = "favour") %>%
mutate(candidate = as.factor(candidate),
favour_percent = str_extract(favour, "\\d+\\.*\\d*")) %>%
mutate(favour_percent = as.integer(favour_percent)) %>%
group_by(dates_format, candidate) %>%
mutate(favour_percent_mean = mean(favour_percent, na.rm = TRUE)) %>%
ungroup() %>%
select(candidate, dates_format, favour_percent_mean)
And we use rbind() to combine the two data.frames
polls <- rbind(feb_poll, early_feb_poll)
Next we repeat with January data:
jan_poll <- poll_tables[[18]]
jan_poll = jan_poll[-34,]
jan_poll = jan_poll[-1,]
jan_poll %<>%
clean_names() %>%
mutate(month = substrRight(fieldwork_date, 3)) %>%
mutate(day_number = parse_number(fieldwork_date)) %>% # drops any non-numeric characters before or after the first number.
unite("date", day_number:month, sep = "", remove = FALSE) %>%
mutate(dates_format = as.Date(date, "%d%b")) %>%
select(dates_format,
Lee = lee_jae_myung,
Yoon = yoon_seok_youl,
Shim = sim_sang_jung,
Ahn = ahn_cheol_soo,
Kim = kim_dong_yeon,
Heo = huh_kyung_young,
others_undecided) %>%
pivot_longer(!dates_format, names_to = "candidate", values_to = "favour") %>%
mutate(candidate = as.factor(candidate),
favour_percent = str_extract(favour, "\\d+\\.*\\d*")) %>%
mutate(favour_percent = as.integer(favour_percent)) %>%
group_by(dates_format, candidate) %>%
mutate(favour_percent_mean = mean(favour_percent, na.rm = TRUE)) %>%
ungroup() %>%
select(candidate, dates_format, favour_percent_mean)
And bind to our combined data.frame:
polls <- rbind(polls, jan_poll)
We can create variables to help us filter different groups of candidates. If we want to only look at the largest candidates, we can makes an important variable and then filter
We can lump the candidates that do not have data from every poll (i.e. the smaller candidate) and add them into the “other_undecided” category with the fct_lump_min() function from the forcats package
polls %>%
mutate(important = ifelse(candidate %in% c("Ahn", "Yoon", "Lee", "Shim"), 1, 0)) %>%
mutate(few_candidate = fct_lump_min(candidate, min = 110, other_level = "others_undecided")) %>%
group_by(few_candidate, dates_format) %>%
filter(important == 1) -> poll_dataI want to only look at the main two candidates from the main parties that have been polling in the 40% range – Lee and Yoon – as well as the data for Ahn (who recently dropped out and endorsed Yoon).
poll_data %>%
filter(candidate %in% c("Lee", "Yoon", "Ahn")) -> lee_yoon_dataWe take the official party hex colors for the graph and create a vector to use later with the scale_color_manual() function below:
party_palette <- c(
"Ahn" = "#df550a",
"Lee" = "#00a0e2",
"Yoon" = "#e7001f")And we plot the variables.
lee_yoon_data %>%
ggplot(aes(x = dates_format, y = favour_percent_mean,
groups = candidate, color = candidate)) +
geom_line( size = 2, alpha = 0.8) +
geom_point(fill = "#5e6472", shape = 21, size = 4, stroke = 3) +
labs(title = "Polling data for Korean Presidential Election", subtitle = "Source: various polling companies, via Wikipedia") -> poll_graphThe bulk of aesthetics for changing the graph appearance in the theme()
poll_graph + theme(panel.border = element_blank(),
legend.position = "bottom",
text = element_text(size = 15, color = "white"),
plot.title = element_text(size = 40),
legend.title = element_blank(),
legend.text = element_text(size = 50, color = "white"),
axis.text.y = element_text(size = 20),
axis.text.x = element_text(size = 20),
legend.background = element_rect(fill = "#5e6472"),
axis.title = element_blank(),
axis.text = element_text(color = "white", size = 20),
panel.grid.major.y = element_blank(),
panel.grid.minor.y = element_blank(),
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
legend.key = element_rect(fill = "#5e6472"),
plot.background = element_rect(fill = "#5e6472"),
panel.background = element_rect(fill = "#5e6472")) +
scale_color_manual(values = party_palette)
Last, with the annotate() functions, we can also add an annotation arrow and text to add some more information about Ahn Cheol-su the candidate dropping out.
annotate("text", x = as.Date("2022-02-11"), y = 13, label = "Ahn dropped out just as the polling blackout began", size = 10, color = "white") +
annotate(geom = "curve", x = as.Date("2022-02-25"), y = 13, xend = as.Date("2022-03-01"), yend = 10,
curvature = -.3, arrow = arrow(length = unit(2, "mm")), size = 1, color = "white")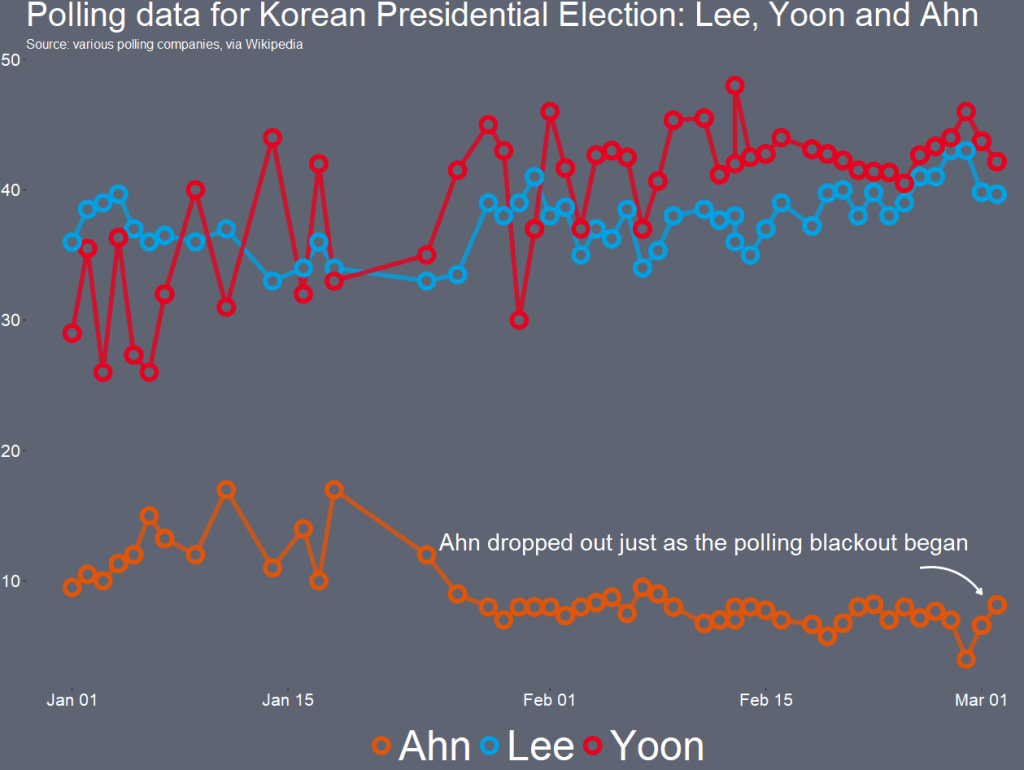
We will just have to wait until next Wednesday / Thursday to see who is the winner ~

