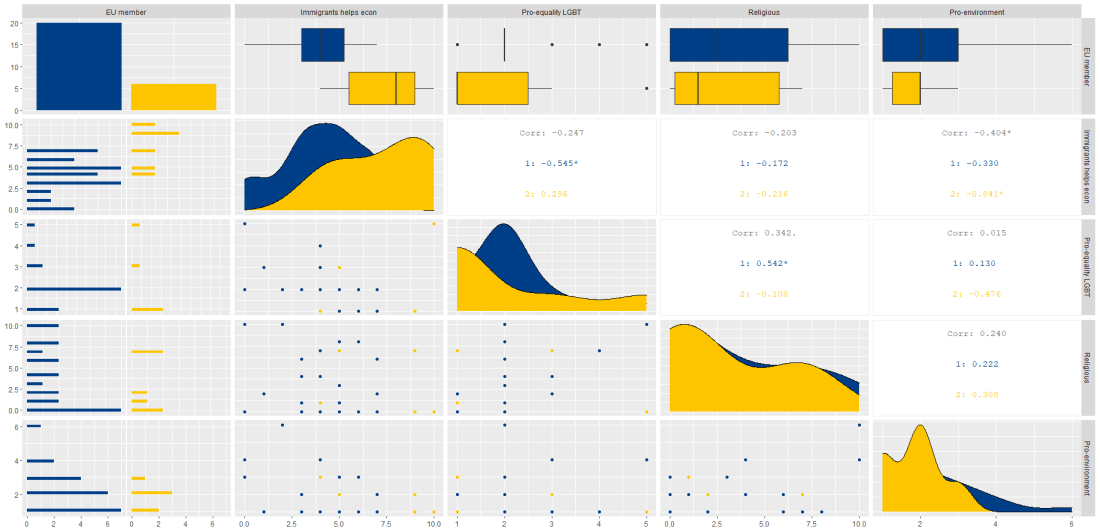
Next, we can go create a dichotomous factor variable and divide the continuous “freedom from torture scale” variable into either above the median or below the median score. It’s a crude measurement but it serves to highlight trends.
Blue means the country enjoys high freedom from torture. Yellow means the county suffers from low freedom from torture and people are more likely to be tortured by their government.
Then we feed our variables into the ggpairs() function from the GGally package.
I use the columnLabels to label the graphs with their full names and the mapping argument to choose my own color palette.
I add the bbc_style() format to the corr_matrix object because I like the font and size of this theme. And voila, we have our basic correlation matrix (Figure 1).
First off, in Figure 2 we can see the centre plots in the diagonal are the distribution plots of each variable in the matrix
Figure 2.
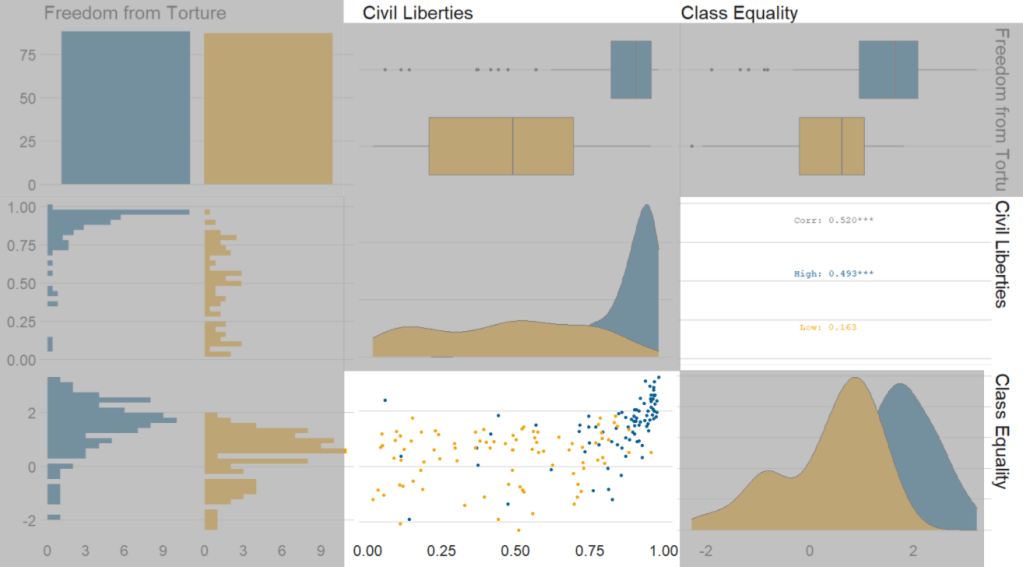
In Figure 3, we can look at the box plot for the ‘civil liberties index’ score for both high (blue) and low (yellow) ‘freedom from torture’ categories.
The median civil liberties score for countries in the high ‘freedom from torture’ countries is far higher than in countries with low ‘freedom from torture’ (i.e. citizens in these countries are more likely to suffer from state torture). The spread / variance is also far great in states with more torture.
Figure 3.
In Figur 4, we can focus below the diagonal and see the scatterplot between the two continuous variables – civil liberties index score and class equality index scores.
We see that there is a positive relationship between civil liberties and class equality. It looks like a slightly U shaped, quadratic relationship but a clear relationship trend is not very clear with the countries with higher torture prevalence (yellow) showing more randomness than the countries with high freedom from torture scores (blue).
Saying that, however, there are a few errant blue points as outliers to the trend in the plot.
The correlation score is also provided between the two categorical variables and the correlation score between civil liberties and class equality scores is 0.52.
Examining at the scatterplot, if we looked only at countries with high freedom from torture, this correlation score could be higher!
We can all agree that Wikipedia is often our go-to site when we want to get information quick. When we’re doing IR or Poli Sci reesarch, Wikipedia will most likely have the most up-to-date data compared to other databases on the web that can quickly become out of date.
So in R, we can scrape a table from Wikipedia and turn into a database with the rvest package .
First, we copy and paste the Wikipedia page we want to scrape into the read_html() function as a string:
Next we save all the tables on the Wikipedia page as a list. Turn the header = TRUE.
nato_tables <- nato_members %>% html_table(header = TRUE, fill = TRUE)
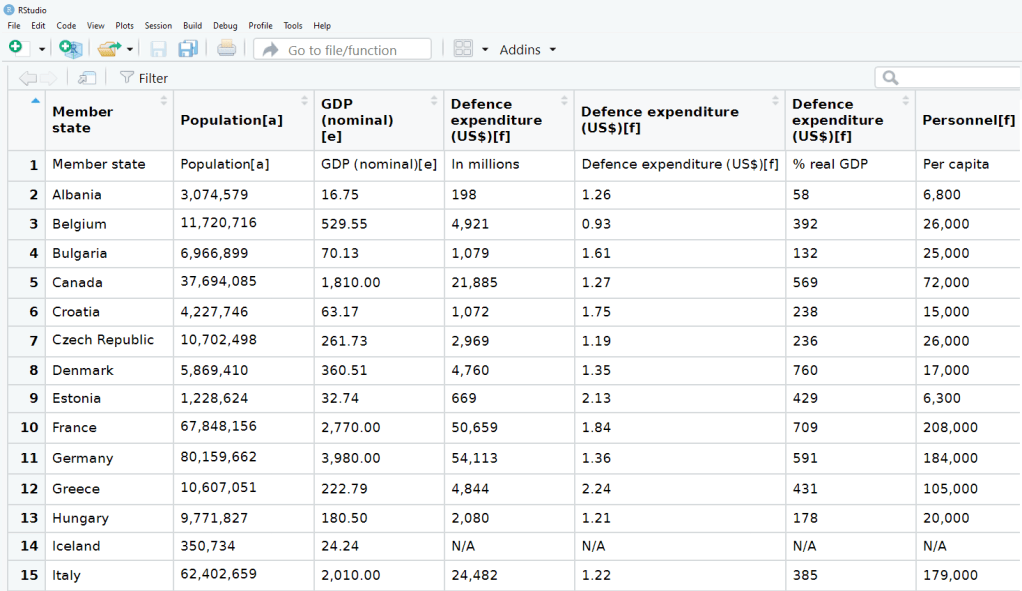
The table that I want is the third table on the page, so use [[two brackets]] to access the third list.
nato_exp <- nato_tables[[3]]
The dataset is not perfect, but it is handy to have access to data this up-to-date. It comes from the most recent NATO report, published in 2019.
Some problems we will have to fix.
The first row is a messy replication of the header / more information across two cells in Wikipedia.
The headers are long and convoluted.
There are a few values in as N/A in the dataset, which R thinks is a string.
All the numbers have commas, so R thinks all the numeric values are all strings.
There are a few NA values that I would not want to impute because they are probably zero. Iceland has no armed forces and manages only a small coast guard. North Macedonia joined NATO in March 2020, so it doesn’t have all the data completely.
So first, let’s do some quick data cleaning:
Clean the variable names to remove symbols and adds underscores with a function from the janitor package
Next turn all the N/A value strings to NULL. The na_strings object we create can be used with other instances of pesky missing data varieties, other than just N/A string.
Remove all the commas from the number columns and convert the character strings to numeric values with a quick function we apply to all numeric columns in the data.frame.
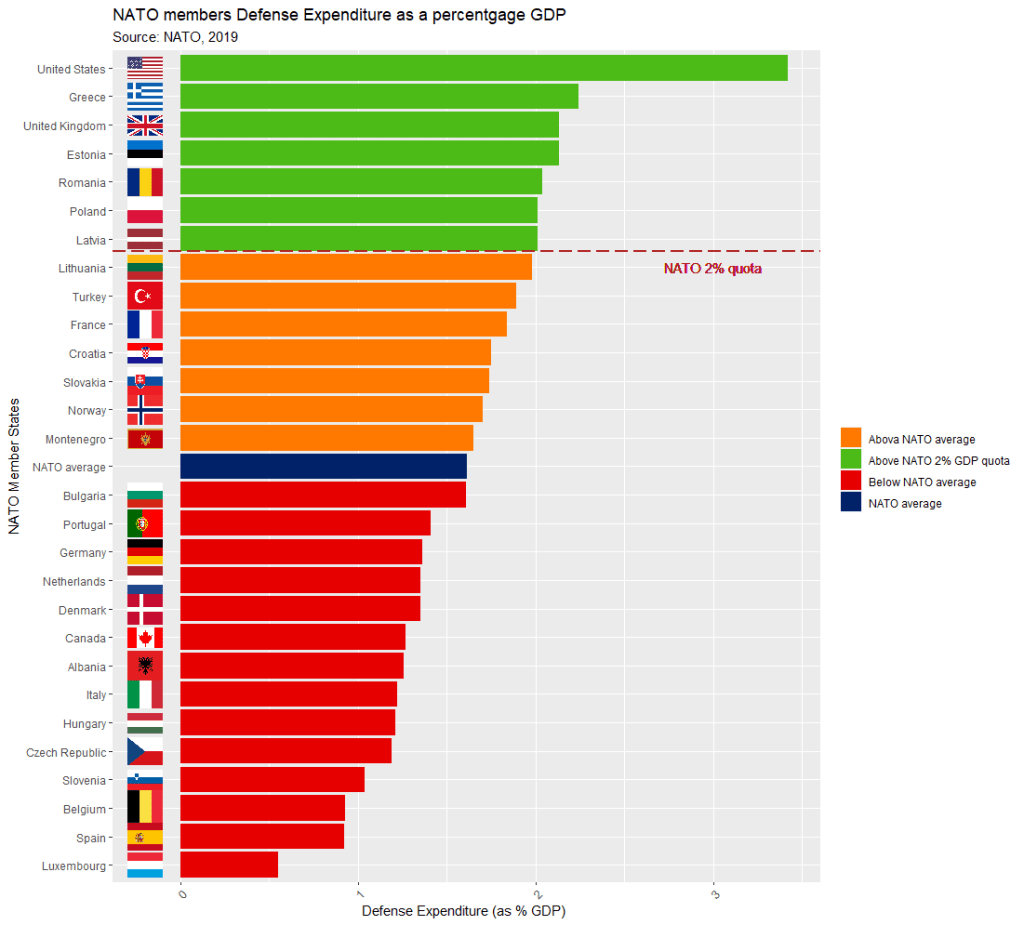
Next, we can calculate the average NATO score of all the countries (excluding the member_state variable, which is a character string).
We’ll exclude the NATO total column (as it is not a member_state but an aggregate of them all) and the data about Iceland and North Macedonia, which have missing values.