Packages we will need:
library(tidyverse)
library(bubbles)
library(treemapify)
library(democracyData)
library(magrittr)In this blog, we will look at different types of charts that we can run in R.

Both the bubble and treemap charts are simple to run.
Before we begin, we will choose some hex colors for the palette. I always use the coolors palettes website to find nice colours.
pal <- c("#bc4749", "#005f73",
"#0a9396", "#94d2bd",
"#bb3e03","#003049",
"#fca311", "#99d98c",
"#9a5059", "#ee9b00")First, we can download the data we will graph.
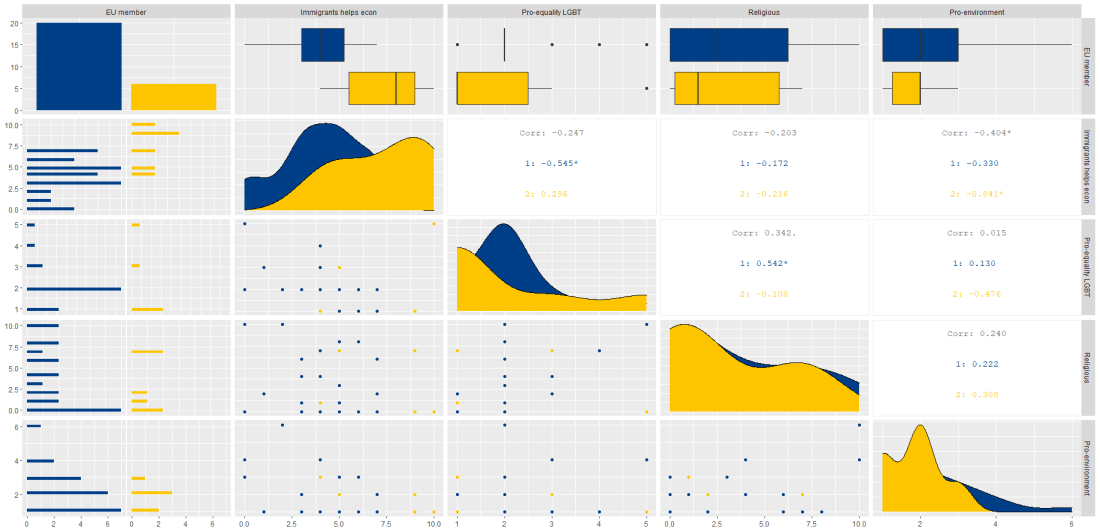
In this case, we will use the DD (democracies and dictatorships) regime data from PACL dataset on different government regimes.
The DD dataset encompasses annual data points for 199 countries spanning from 1946 to 2008. The visual representations on the left illustrate the outcomes in 1988 and 2008.
Cheibub, Gandhi, and Vreeland devised a six-fold regime classification scheme, giving rise to what they termed the DD datasets. The DD index categorises regimes into two types: democracies and dictatorships.
Democracies are divided into three types: parliamentary, semi-presidential, and presidential democracies.
Dictatorships are subcategorized into monarchic, military, and civilian dictatorship.
democracyData::pacl -> paclFirst, we create a new variable with the regime names, not just the number. The values come from the codebook.

pacl %<>%
mutate(regime_name = ifelse(regime == 0, "Parliamentary democracies",
ifelse(regime == 1, "Mixed democracies",
ifelse(regime == 2, "Presidential democracies",
ifelse(regime == 3, "Civilian autocracies",
ifelse(regime == 4, "Military dictatorships",
ifelse(regime == 5,"Royal dictatorships", regime))))))) %>%
mutate(regime = as.factor(regime))
order pacl_country year regime_name
<dbl> <chr> <dbl> <chr>
1 1 Afghanistan 1946 Royal dictatorships
2 2 Afghanistan 1947 Royal dictatorships
3 3 Afghanistan 1948 Royal dictatorships
4 4 Afghanistan 1949 Royal dictatorships
5 5 Afghanistan 1950 Royal dictatorships
6 6 Afghanistan 1951 Royal dictatorships
We want to count the number of different regime types.
pacl %>%
group_by(regime_name) %>%
count() -> pacl_countWe can graph out the geom_treemap() layer in the ggplot() object
pacl_count %>%
ggplot(aes(area = n, fill = regime_name,
label = paste(regime_name, n, sep = "\n"))) +
geom_treemap(color = "white", size = 3) +
geom_treemap_text(
place = "centre",
size = 20) +
theme(legend.position = "none") +
scale_fill_manual(values = sample(pal)) 
And we can use the bubbles() function from the bubbles package.
Unfortunately, it is not pipable into ggplot, so it is hard to edit factors such as the font size.
bubbles::bubbles(label = pacl_count$regime_name,
value = pacl_count$n,
color = sample(pal, size = length(pacl_count$regime_name)))
Thank you for reading!