rowwise(): This function is used to indicate that operations following it should be applied row by row instead of column by column (which is the default behavior in dplyr).
Within the mutate() function, sum(c_across(contains("totals_"))) computes the sum of all columns for each row that contain the pattern “totals_”.
The na.rm = TRUE argument is used to ignore NA values in the sum. c_across() is used to select columns within rowwise() context.
ungroup(): This function is used to remove the rowwise grouping imposed by rowwise(), returning the dataframe to a standard tbl_df.
Usually I forget to ungroup. Oops. But this is important for performance reasons and because most dplyr functions expect data not to be in a rowwise format.
Create a rowwise binary variable
data <- data %>%
rowwise() %>%
mutate(has_ruler = as.integer(any(c_across(starts_with("broad_cat_")) == "ruler"))) %>%
ungroup()
library(tidyverse) # of course
library(ggridges) # density plots
library(GGally) # correlation matrics
library(stargazer) # tables
library(knitr) # more tables stuff
library(kableExtra) # more and more tables
library(ggrepel) # spread out labels
library(ggstream) # streamplots
library(bbplot) # pretty themes
library(ggthemes) # more pretty themes
library(ggside) # stack plots side by side
library(forcats) # reorder factor levels
Before jumping into any inferentional statistical analysis, it is helpful for us to get to know our data.
That always means plotting and visualising the data and looking at the spread, the mean, distribution and outliers in the dataset.
Before we plot anything, a simple package that creates tables in the stargazer package. We can examine descriptive statistics of the variables in one table.
Click here to read this practically exhaustive cheat sheet for the stargazer package by Jake Russ. I refer to it at least once a week. Thank you, Jack.
I want to summarise a few of the stats, so I write into the summary.stat() argument the number of observations, the mean, median and standard deviation.
The kbl() and kable_classic() will change the look of the table in R (or if you want to copy and paste the code into latex with the type = "latex" argument).
In HTML, they do not appear.
To find out more about the knitr kable tables, click here to read the cheatsheet by Hao Zhu.
Choose the variables you want, put them into a data.frame and feed them into the stargazer() function
stargazer(my_df_summary,
covariate.labels = c("Corruption index",
"Civil society strength",
'Rule of Law score',
"Physical Integerity Score",
"GDP growth"),
summary.stat = c("n", "mean", "median", "sd"),
type = "html") %>%
kbl() %>%
kable_classic(full_width = F, html_font = "Times", font_size = 25)
Statistic
N
Mean
Median
St. Dev.
Corruption index
179
0.477
0.519
0.304
Civil society strength
179
0.670
0.805
0.287
Rule of Law score
173
7.451
7.000
4.745
Physical Integerity Score
179
0.696
0.807
0.284
GDP growth
163
0.019
0.020
0.032
Next, we can create a barchart to look at the different levels of variables across categories. We can look at the different regime types (from complete autocracy to liberal democracy) across the six geographical regions in 2018 with the geom_bar().
my_df %>%
filter(year == 2018) %>%
ggplot() +
geom_bar(aes(as.factor(region),
fill = as.factor(regime)),
color = "white", size = 2.5) -> my_barplot
This type of graph also tells us that Sub-Saharan Africa has the highest number of countries and the Middle East and North African (MENA) has the fewest countries.
However, if we want to look at each group and their absolute percentages, we change one line: we add geom_bar(position = "fill"). For example we can see more clearly that over 50% of Post-Soviet countries are democracies ( orange = electoral and blue = liberal democracy) as of 2018.
We can also check out the density plot of democracy levels (as a numeric level) across the six regions in 2018.
With these types of graphs, we can examine characteristics of the variables, such as whether there is a large spread or normal distribution of democracy across each region.
Click here to read more about the GGally package and click here to read their CRAN PDF.
We can use the ggside package to stack graphs together into one plot.
There are a few arguments to add when we choose where we want to place each graph.
For example, geom_xsideboxplot(aes(y = freedom_house), orientation = "y") places a boxplot for the three Freedom House democracy levels on the top of the graph, running across the x axis. If we wanted the boxplot along the y axis we would write geom_ysideboxplot(). We add orientation = "y" to indicate the direction of the boxplots.
Next we indiciate how big we want each graph to be in the panel with theme(ggside.panel.scale = .5) argument. This makes the scatterplot take up half and the boxplot the other half. If we write .3, the scatterplot takes up 70% and the boxplot takes up the remainning 30%. Last we indicade scale_xsidey_discrete() so the graph doesn’t think it is a continuous variable.
We add Darjeeling Limited color palette from the Wes Anderson movie.
Click here to learn about adding Wes Anderson theme colour palettes to graphs and plots.
The next plot will look how variables change over time.
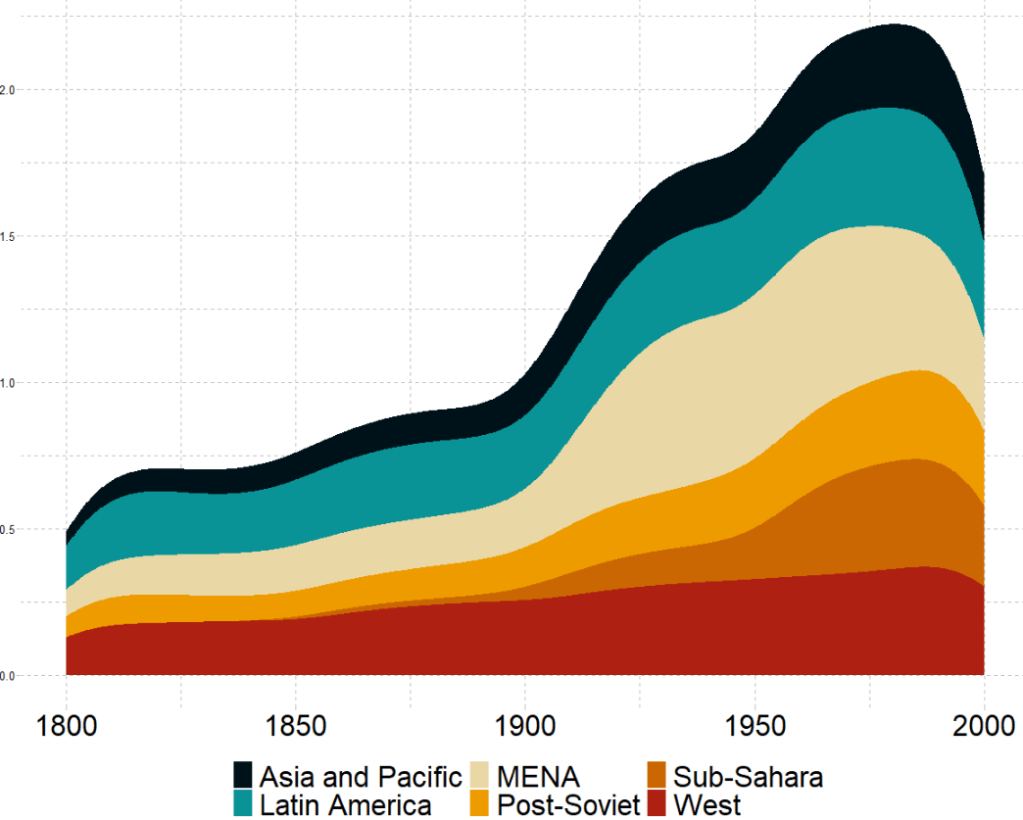
We can check out if there are changes in the volume and proportion of a variable across time with the geom_stream(type = "ridge") from the ggstream package.
In this instance, we will compare urban populations across regions from 1800s to today.
Click here to read more about the ggstream package and click here to read their CRAN PDF.
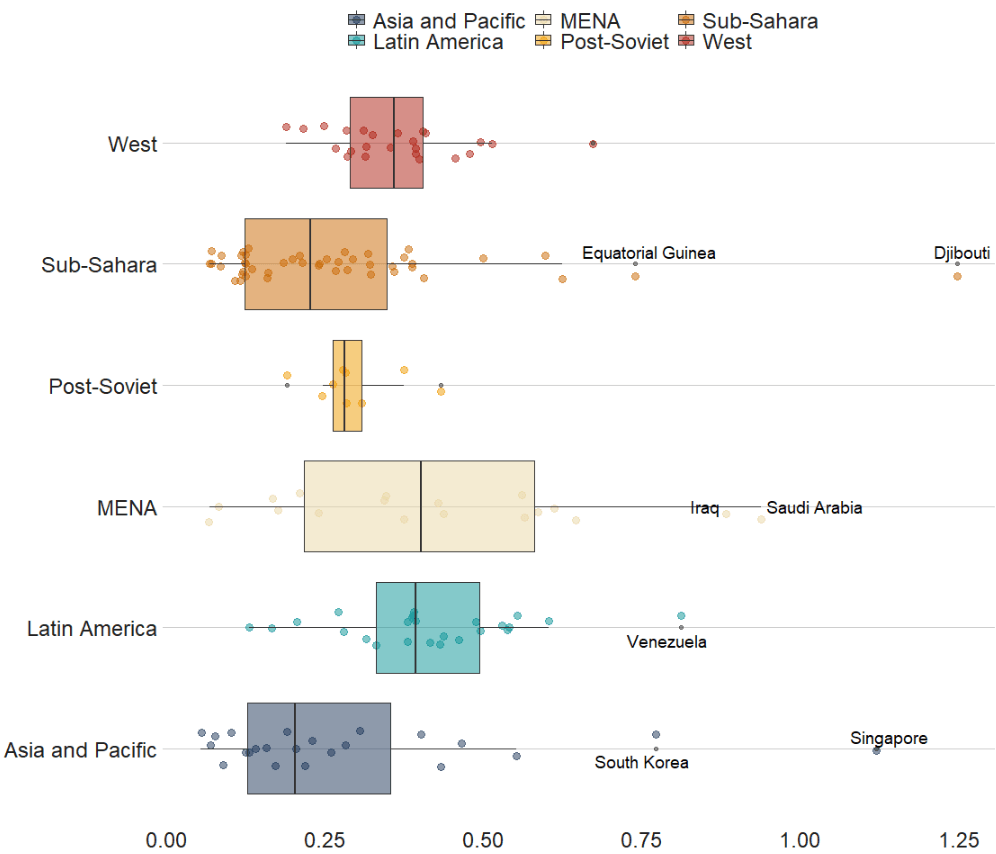
We can also look at interquartile ranges and spread across variables.
We will look at the urbanization rate across the different regions. The variable is calculated as the ratio of urban population to total country population.
Before, we will create a hex color vector so we are not copying and pasting the colours too many times.
If we want to look more closely at one year and print out the country names for the countries that are outliers in the graph, we can run the following function and find the outliers int he dataset for the year 1990:
In the next blog post, we will look at t-tests, ANOVAs (and their non-parametric alternatives) to see if the difference in means / medians is statistically significant and meaningful for the underlying population.