In this case, we will use the DD (democracies and dictatorships) regime data from PACL dataset on different government regimes.
The DD dataset encompasses annual data points for 199 countries spanning from 1946 to 2008. The visual representations on the left illustrate the outcomes in 1988 and 2008.
Cheibub, Gandhi, and Vreeland devised a six-fold regime classification scheme, giving rise to what they termed the DD datasets. The DD index categorises regimes into two types: democracies and dictatorships.
Democracies are divided into three types: parliamentary, semi-presidential, and presidential democracies.
Dictatorships are subcategorized into monarchic, military, and civilian dictatorship.
democracyData::pacl -> pacl
First, we create a new variable with the regime names, not just the number. The values come from the codebook.
The World Development Indicators (WDI) package by Vincent Arel-Bundock provides access to a database of hundreds of economic development indicators from the World Bank.
Examples of variables include population, GDP, education, health, and poverty, school attendance rates.
Reference: Arel-Bundock, V. (2017). WDI: World Development Indicators (R Package Version 2.7.1).
This package by Steve Miller helps you download data related to peace and conflict studies, including the Correlates of War project.
Examples of variables include Alliance Treaty Obligations and Provisions (ATOP), Thompson and Dreyer’s (2012) strategic rivalry data, fractionalization/polarization estimates from the Composition of Religious and Ethnic Groups (CREG) Project, and Uppsala Conflict Data Program (UCDP) data on civil and inter-state conflicts.
Data can come in either country-year, event-level or dyadic-level.
eurostat provides access to a wide range of statistics and data on the European Union and its member states, covering topics such as population, economics, society, and the environment.
Examples of variables include employment, inflation, education, crime, and air pollution. The package was authored by Leo Lahti.
The Varieties of Democracy package by Staffan I. Lindberg et al. provides data on a range of indicators related to democracy and governance in countries around the world, including measures of electoral democracy, civil liberties, and human rights.
Examples of variables include freedom of speech, rule of law, corruption, government transparency, and voter turnout.
Reference: Lindberg, S. I., & Stepanova, N. (2020). vdem: Varieties of Democracy Project (R Package Version 1.6).
5. democracyData
This package by Xavier Marquez: provides data on a range of variables related to democracy, including elections, political parties, and civil liberties.
This package by Frederick Solt provides a simple way to download and import data from the Inter-university Consortium for Political and Social Research (ICPSR) archive into R. This is for easy replication and sharing of data. The package includes datasets from different fields of study, including sociology, political science, and economics.
Reference: Solt, F. (2020). icpsrdata: Reproducible Data Retrieval from the ICPSR Archive (R Package Version 0.5.0).
7. Quandl
This R package by Quandl provides an interface to access financial and economic data from over 20 different sources. Examples of variables include stock prices, futures, options, and macroeconomic indicators. The package includes functions to easily download data directly into R and perform tasks such as plotting, transforming, and aggregating data. Additional functions for managing and exploring data, such as search tools and data caching features, are also available.
Here are five examples of variables in the Quandl package:
The essurvey package is an R package that provides access to data from the European Social Survey (ESS), which is a large-scale survey that collects data on attitudes, values, and behavior across Europe. The package includes functions to easily download, read, and analyze data from the ESS, and also includes documentation and sample code to help users get started.
Examples of variables in the ESS dataset include political interest, trust in political institutions, social class, education level, and income. The package was authored by David Winter and includes a variety of useful functions for working with ESS data.
Reference: Winter, D. (2021). essurvey: Download Data from the European Social Survey on the Fly. R package version 3.4.4. Retrieved from https://cran.r-project.org/package=essurvey.
manifestoR is an R package that provides access to data from the Comparative Manifesto Project (CMP), which is a cross-national research project that analyzes political party manifestos. The package allows users to easily download and analyze data from the CMP, including party positions on various policy issues and the salience of those issues across time and space.
Examples of variables in the CMP dataset include party positions on taxation, immigration, the environment, healthcare, and education. The package was authored by Jörg Matthes, Marcelo Jenny, and Carsten Schwemmer.
Reference: Matthes, J., Jenny, M., & Schwemmer, C. (2018). manifestoR: Access and Process Data and Documents of the Manifesto Project. R package version 1.2.1. Retrieved from https://cran.r-project.org/package=manifestoR.
The unvotes data package provides historical voting data of the United Nations General Assembly, including votes for each country in each roll call, as well as descriptions and topic classifications for each vote.
The classifications included in the dataset cover a wide range of issues, including human rights, disarmament, decolonization, and Middle East-related issues.
The gravity package in R, created by Anna-Lena Woelwer, provides a set of functions for estimating gravity models, which are used to analyze bilateral trade flows between countries. The package includes the gravity_data dataset, which contains information on trade flows between pairs of countries.
Examples of variables that may affect trade in the dataset are GDP, distance, and the presence of regional trade agreements, contiguity, common official language, and common currency.
iso_o: ISO-Code of country of origin iso_d: ISO-Code of country of destination distw: weighted distance gdp_o: GDP of country of origin gdp_d: GDP of country of destination rta: regional trade agreement flow: trade flow contig: contiguity comlang_off: common official language comcur: common currency
When you come across data from the World Bank, often it is messy.
So this blog will go through how to make it more tidy and more manageable in R
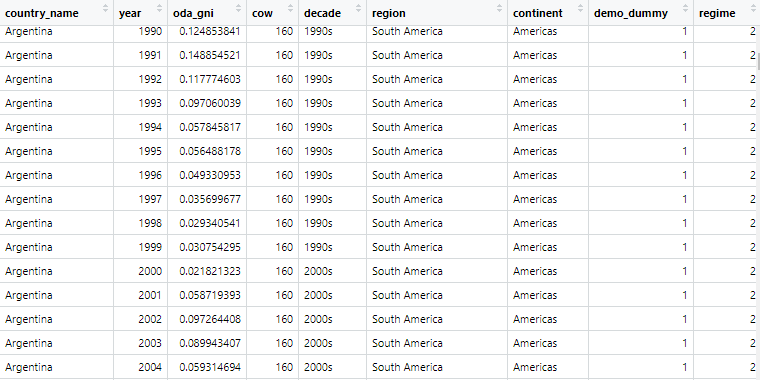
For this blog, we will look at World Bank data on financial aid. Specifically, we will be using values for net ODA received as percentage of each country’s GNI. These figures come from the Development Assistance Committee of the Organisation for Economic Co-operation and Development (DAC OECD).
The year values are character strings, not numbers. So we will convert with parse_number(). This parses the first number it finds, dropping any non-numeric characters before the first number and all characters after the first number.
oda %>%
mutate(year = parse_number(year)) -> oda
Next we will move from the year variable to ODA variable. There are many ODA values that are empty. We can see that there are 145 instances of empty character strings.
oda %>%
count(oda_gni) %>%
arrange(oda_gni)
So we can replace the empty character strings with NA values using the na_if() function. Then we can use the parse_number() function to turn the character into a string.
oda %>%
mutate(oda_gni = na_if(oda_gni, "")) %>%
mutate(oda_gni = parse_number(oda_gni)) -> oda
Now we need to delete the year variables that have no values.
oda %<>%
filter(!is.na(year))
Also we need to delete non-countries.
The dataset has lots of values for regions that are not actual countries. If you only want to look at politically sovereign countries, we can filter out countries that do not have a Correlates of War value.
oda %<>%
mutate(cow = countrycode(oda$country_name, "country.name", 'cown')) %>%
filter(!is.na(cow))
We can also make a variable for each decade (1990s, 2000s etc).
For this blog post, we will look at UN peacekeeping missions and compare across regions.
Despite the criticisms about some operations, the empirical record for UN peacekeeping records has been robust in the academic literature
“In short, peacekeeping intervenes in the most difficult cases, dramatically increases the chances that peace will last, and does so by altering the incentives of the peacekept, by alleviating their fear and mistrust of each other, by preventing and controlling accidents and misbehavior by hard-line factions, and by encouraging political inclusion” (Goldstone, 2008: 178).
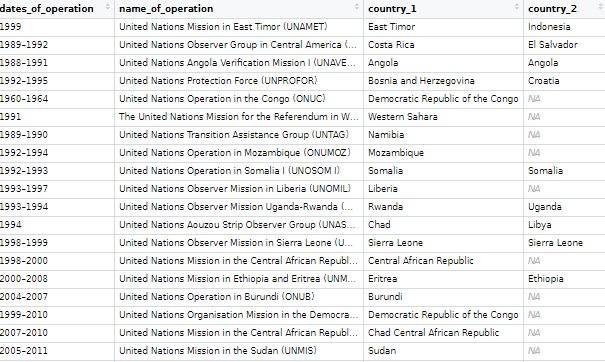
The data on the current and previous PKOs (peacekeeping operations) will come from the Wikipedia page. But the variables do not really lend themselves to analysis as they are.
Once we have the url, we scrape all the tables on the Wikipedia page in a few lines
We then bind the completed and current mission data.frames
rbind(pko_complete, pko_current) -> pko
Then we clean the variable names with the function from the janitor package.
pko_df <- pko %>%
janitor::clean_names()
Next we’ll want to create some new variables.
We can make a new row for each country that is receiving a peacekeeping mission. We can paste all the countries together and then use the separate function from the tidyr package to create new variables.
pko_countries %>%
ggplot(mapping = aes(x = decade,
y = duration,
fill = decade)) +
geom_boxplot(alpha = 0.4) +
geom_jitter(aes(color = decade),
size = 6, alpha = 0.8, width = 0.15) +
coord_flip() +
geom_curve(aes(x = "1950s", y = 60, xend = "1940s", yend = 72),
arrow = arrow(length = unit(0.1, "inch")), size = 0.8, color = "black",
curvature = -0.4) +
annotate("text", label = "First Mission to Kashmir",
x = "1950s", y = 49, size = 8, color = "black") +
geom_curve(aes(x = "1990s", y = 46, xend = "1990s", yend = 32),
arrow = arrow(length = unit(0.1, "inch")), size = 0.8, color = "black",curvature = 0.3) +
annotate("text", label = "Most Missions after the Cold War",
x = "1990s", y = 60, size = 8, color = "black") +
bbplot::bbc_style() + ggtitle("Duration of Peacekeeping Missions")
Years
Following the end of the Cold War, there were renewed calls for the UN to become the agency for achieving world peace, and the agency’s peacekeeping dramatically increased, authorizing more missions between 1991 and 1994 than in the previous 45 years combined.
We can use a waffle plot to see which decade had the most operation missions. Waffle plots are often seen as more clear than pie charts.
To get the data ready for a waffle chart, we just need to count the number of peacekeeping missions (i.e. the number of rows) in each decade. Then we fill the groups (i.e. decade) and enter the n variable we created as the value.